Level: Beginner; Time spent to get here: 2 hours;
Skills involved: Setting arrays to store values; sorting and printing values through loops
I may be reinventing the wheels, but I want to know how a frequency list works.
This post is not intended for programmers (‘Rubyists’). This is for you and me – the laypeople who wish to see how programming helps with our work. This small programming ‘project’ on Codecademy creates a simple program for counting the numbers of words in a string of text. Corpus tools like WordSmith and WMatrix have frequency lists functions, but if we can figure out how it works and develop programs that visualise the word list, it can be very cool. I also know NLTK with Python is also a very powerful tool; my friend Daniel is an expert on this and has his own repositories on GitHub. I’m afraid I’m letting him down as I’m not working on my iPython repertoires any further, but I promise myself I’ll go back there as soon as I can.
I only spent 15 – 30 minutes a day to get here. It is an exhilarating experience to be had – I figured this out in only 2 hours, and I did it myself (with the step-by-step guidance in the course)! 15 – 30 minutes comes to three pomodoro breaks, or the 30 minutes before sleep. I may have spent an hour on Netflix, but just 15 minutes can make a difference, so it’s worth the time. I do not usually remember what I have learnt because I only intend to memorise the things I need for my thesis. I leave these skills in my notebook, and flip through it when I need the particular skill. It can cause some discomfort at the beginning, since we’ve been taught to ‘remember’ things as we learn. Well, if you know you are going to use the skill often, you remember them through drilling until it becomes your instinct.
The picture captures how I did it, and I made notes about how it’s done line by line below. If you are more interested in the output feel free scroll down to the bottom of the post to see the output: no fancy visualisations (yet), but just an idea of how we can find out the most frequent words occurring in a text.
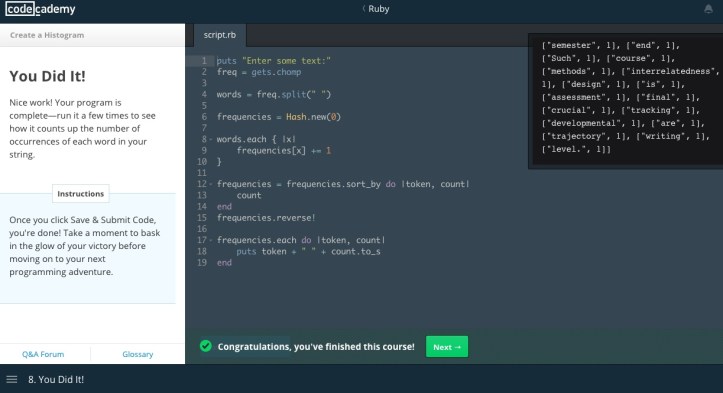
Line 1: Prompts input
Line 2: Reads input, and saving the input to the variable “freq”
E.g. My input “the rain in Spain stays mainly in the plain” is now saved in “freq”
Line 4: Splits the string in “freq” by white space to obtain separate words and saves these words in a new variable “words”
E.g. The string “the rain in Spain stays in the plain” is splitted into “the/rain/in/Spain/stays/mainly/in/the/plain”
Line 6: Sets up a new variable “frequencies” to save the words as separate “keys”; the “default value” of each “key” is set as zero as the data is not analysed yet
E.g. The words obtained in Line 4 will become the keys in “frequencies”; the initial value of these keys is zero as the string is not counted yet.
Line 8 – 10: Each word in the variable “words” becomes the name of the “key” in the variable “frequencies”; the value of the key increases by 1
E.g. The work starts here: the string is read by the program. “the” (in lower case) appears twice in the string, so the key “the” will carry the value “2”
Line 12 – 15: Assign the names that call out the keys and values of “frequencies” as “token” and “count”; sort “frequencies” by “count” (in ascending order), and reverse the variable in descending order.
E.g. By now we have “frequencies” filled with keys and values [[rain, 1], [Spain, 1], [stays, 1], [mainly, 1], [plain, 1], [the, 2], [in, 2]] (they call this ‘an array of arrays’). This array is rearranged in descending order.
Line 17 – 19: Sets up a loop to print out the keys and values in the array as a simple frequency list. The numerical values are converted into text strings to be printed with the keys.
E.g. The “puts” command prints each array in a separate line. The result is something like this:
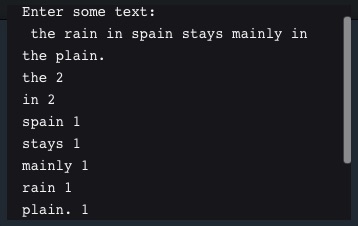
No doubt we expect to see function words (‘grammatical class’) appear more frequently in a text, even in a short sentence like this. The next steps I hope to achieve is:
- Removing punctuations (so “plain” and “plain.” are both counted as “plain”, 2 counts);
- Ignoring cases (so “The” and “the” are 2 instances of “the”)
- Splitting a text by sentences (so the point of the program gets closer to help me do clause-by-clause analyses)
I’m sure many of you may know how to do them. Please feel free to share your coding experience – do you do it to make your work easier/more fun/more professional? How does programming help? Let me know!
So much for now. Until next time! :)
